A la hora de construir una web, dos de los factores que más se pasan por alto y que va a influir directamente en el rendimiento orgánico de ésta, son el rastreo y la indexación.
Muchas veces nos enfocamos en palabras clave, backlinks y contenido de calidad, y en aspectos más visibles como el diseño, las animaciones o la experiencia visual de una web, y sin embargo, todo esto no vale si Google no puede “leer” tu página web.
El rastreo y la indexación son dos procesos fundamentales en el funcionamiento de buscadores como Google, Bing, y otros. A continuación te explicaremos estos términos y sus aspectos clave.
Que es el rastreo
El rastreo (o crawling) es el proceso en el que los motores de búsqueda exploran la web utilizando elementos llamados rastreadores o bots (por ejemplo, Googlebot). Estos bots visitan sitios web, siguen enlaces y recopilan información sobre el contenido de las páginas.
Comienzan desde URLs conocidas y siguen enlaces para descubrir nuevas páginas, analizando elementos como contenido, textos ancla, o imágenes. Googlebot no solo sigue los enlaces y recoge contenido estático, sino que también renderiza el contenido dinámico generado por JavaScript, lo que permite analizar páginas más complejas. Esto es importante porque muchos sitios web utilizan JavaScript para cargar contenido adicional, lo que podría no ser detectado si no se renderiza.
Si los bots no pueden rastrear tu sitio, no podrán indexarlo ni mostrarlo en los resultados de búsqueda. Por eso, es clave facilitar el rastreo con una estructura clara y herramientas como el archivo robots.txt y el sitemap XML.
Que es la indexación
La indexación es el proceso en el que los buscadores organizan y almacenan la información recopilada durante el rastreo en una base de datos llamada índice (index). Este índice es como un catálogo masivo donde los motores de búsqueda almacenan sus datos para posteriormente mostrar como resultados relevantes a las consultas de los usuarios.
Si el rastreo es el acto de encontrar tu página, la indexación es el proceso de archivarla y clasificarla. Si tu contenido es relevante y cumple con los requisitos de calidad, será indexado y podrá aparecer en los resultados cuando un usuario haga una búsqueda relacionada.
Sin embargo, no todas las páginas que se rastrean terminan indexándose. Si Google, u otro buscador, considera que una página tiene contenido duplicado, pobre o irrelevante, puede optar por no incluirla en su índice.

Diferencia
- Rastreo: Los bots exploran tu sitio web para descubrir contenido.
- Indexación: El contenido descubierto se almacena en el índice del motor de búsqueda.
Ambos procesos son esenciales para que tu sitio web sea visible en los resultados de búsqueda.
Por qué son tan importantes
El rastreo y la indexación son esenciales para el SEO y la visibilidad de tu sitio web. El rastreo permite que los bots de los motores de búsqueda descubran tu contenido, mientras que la indexación lo muestra en los resultados de búsqueda.
Para que estos procesos funcionen bien, es vital tener en cuenta aspectos clave como una arquitectura web clara que facilite el rastreo y herramientas como el archivo robots.txt y el sitemap XML. Además, el contenido debe ser de alta calidad: único, relevante y libre de errores técnicos y sobretodo y mas importante, cumplir la intención de búsqueda del usuario.
Estos filtros aseguran que solo las páginas útiles se indexen, lo que mejora la experiencia del usuario al mostrar resultados buenos y relevantes. A continuación desgranamos estos aspectos clave.
Aspectos claves del rastreo
Archivo robots.txt. Es un archivo de texto ubicado en el directorio raíz de tu sitio web que indica a los bots de los motores de búsqueda qué páginas o secciones pueden rastrear y cuáles no.
Es una herramienta esencial para controlar el acceso de los rastreadores a contenido sensible o irrelevante, como páginas de administración o archivos privados.

Sin embargo, si se configura incorrectamente, puede bloquear accidentalmente el acceso a páginas importantes, lo que afectaría negativamente a tu SEO.
Sitemap XML. Es un archivo que enumera todas las páginas importantes de tu sitio web, proporcionando a los bots una guía clara de lo que deben rastrear.
Es especialmente útil para sitios web grandes o con estructuras complejas, ya que asegura que los bots no pasen por alto páginas clave.
Enviar tu sitemap a herramientas como Google Search Console puede acelerar el proceso de rastreo e indexación.
Arquitectura web. Una arquitectura web clara y bien organizada es fundamental para facilitar el rastreo.
La arquitectura web se refiere a cómo están estructuradas y ordenadas las páginas de tu sitio. Una jerarquía lógica, con categorías y subcategorías bien definidas, permite que los bots naveguen fácilmente por tu sitio, encuentren y entiendan todo el contenido importante.
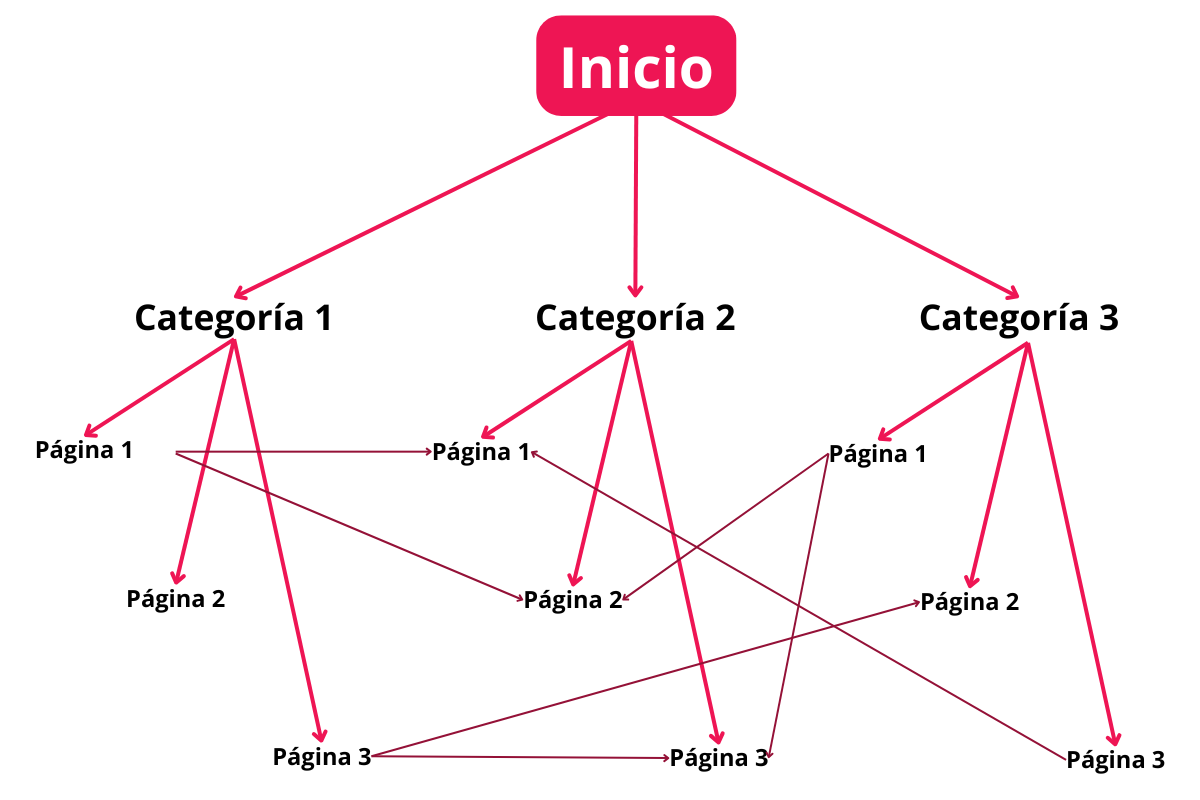
Evita estructuras demasiado profundas o enlaces rotos, ya que pueden dificultar el rastreo y hacer que los bots no descubran páginas clave.
Aspectos relevantes de la indexación
Contenido único y de calidad. Los buscadores priorizan el contenido único, original y de alta calidad. El contenido duplicado, escaso o irrelevante puede ser ignorado o penalizado, lo que afectaría tu indexación.
Etiquetas robots (index y noindex). Las etiquetas robots son directivas que le indican a los motores de búsqueda cómo deben tratar una página específica. Las dos más comunes son index y noindex.
- Index: Indica que la página debe ser indexada y puede aparecer en los resultados de búsqueda. Esta es la opción predeterminada si no se especifica lo contrario.
- Noindex: Indica que la página no debe ser indexada y, por lo tanto, no aparecerá en los resultados de búsqueda. Es útil para páginas que no deseas que sean indexadas, como páginas de prueba, contenido temporal o áreas privadas.
Etiqueta canonical. Etiqueta canonical. Esta etiqueta se utiliza para indicar a los motores de búsqueda cuál es la URL preferida (o «canónica») cuando existen múltiples versiones de una página con contenido idéntico o muy similar (por ejemplo, versiones con y sin www, con parámetros de seguimiento, etc.). Ayuda a consolidar las señales de indexación y autoridad en una única URL, evitando problemas de contenido duplicado.
Es crucial usar estas etiquetas correctamente. Por ejemplo, si accidentalmente colocas noindex en una página importante, esta no se indexará y no será visible en los motores de búsqueda.
Errores técnicos. Problemas técnicos como páginas duplicadas, errores 404 o contenido bloqueado pueden evitar que tus páginas se indexen.
Realiza auditorías técnicas periódicas para identificar y corregir estos problemas, asegurándote de que todas las páginas importantes sean accesibles para los bots.
Autoridad. La autoridad de tu web suele estar determinada por factores como la cantidad y calidad de backlinks. Puede influir en la frecuencia y velocidad de la indexación.
Los sitios con mayor autoridad suelen ser rastreados e indexados más rápido, ya que los motores de búsqueda confían más en su contenido. Construir una sólida red de backlinks y mejorar la reputación de tu sitio son estrategias clave para aumentar su autoridad.
Actualizaciones frecuentes. Los motores de búsqueda prefieren indexar contenido fresco y actualizado, ya que suele ser más relevante para los usuarios.
Publicar contenido nuevo con regularidad y actualizar las páginas existentes puede mejorar la frecuencia de rastreo e indexación de tu sitio. Esto es especialmente importante para sitios que dependen de noticias, eventos o información en constante cambio.
Algoritmos de Google y sus cambios. Los algoritmos de Google, como Panda, Penguin y BERT, han evolucionado significativamente a lo largo de los años, afectando directamente cómo se rastrea, indexa y clasifica el contenido. Por ejemplo:
- Panda (2011): Penaliza los sitios con contenido de baja calidad o duplicado, lo que llevó a los webmasters a enfocarse en crear contenido único y relevante para ser indexado.
- Penguin (2012): Atacó las prácticas de link building manipulativo, lo que reforzó la importancia de la autoridad del sitio y los backlinks de calidad para una indexación efectiva.
- BERT (2019): Mejoró la comprensión del lenguaje natural, lo que significa que Google ahora indexa y clasifica el contenido basándose en su relevancia y contexto, no solo en palabras clave específicas.
Estos cambios han hecho que el rastreo y la indexación sean más inteligentes y exigentes. Hoy, Google prioriza la experiencia del usuario (UX) y la calidad del contenido, lo que significa que los sitios deben estar bien estructurados, ser técnicamente sólidos y ofrecer valor real para ser indexados y posicionados correctamente.
Herramientas para comprobar el rastreo e indexación
Google Search Console.
Usa Google Search Console para identificar errores de rastreo e indexación. Revisa la sección «Cobertura» para ver páginas indexadas y errores comunes, como páginas no encontradas (404) o contenido bloqueado.

Screaming Frog.
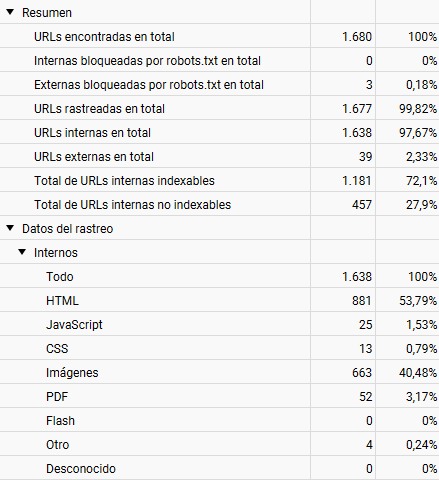
Con Screaming Frog, realiza auditorías técnicas para detectar problemas como enlaces rotos, páginas bloqueadas o contenido duplicado. Es una herramienta esencial para analizar la estructura de tu sitio.
Busca en Google.
Usa el operador site: (por ejemplo, site:tudominio.com) en Google para ver qué páginas de tu sitio están indexadas. Si faltan páginas importantes, puede haber problemas de indexación.

El rastreo y la indexación son esenciales para garantizar que tu sitio web sea accesible y visible en los motores de búsqueda. Sin estos procesos correctamente ejecutados, todo el esfuerzo puede pasar desapercibido para los usuarios.
Optimizar estos aspectos no solo mejora tu posicionamiento, sino que también asegura que tu contenido llegue a quienes más lo necesitan. Si aún no has revisado estos puntos, es el momento perfecto para hacerlo.
En Dobuss, podemos ayudarte a mejorar tu presencia online y asegurar que tu sitio esté optimizado para el éxito. ¡Contáctanos ahora!